MySQL案例-mysqld got signal 11
发布时间:2022-06-30 13:34 所属栏目:115 来源:互联网
导读:背景: MySQL-5.7.12, debian 8核16G虚拟机, 业务方反馈在某一个时间点, 出现了大量的数据库报错, 之后恢复正常; 场景: 开发查看日志后, 发现在某个时间点, 应用断开了所有与数据库的连接, 几秒钟以后就恢复了; 同时监控系统的内存使用率出现了异常的骤降; My
|
背景: MySQL-5.7.12, debian 8核16G虚拟机, 业务方反馈在某一个时间点, 出现了大量的数据库报错, 之后恢复正常; 场景: 开发查看日志后, 发现在某个时间点, 应用断开了所有与数据库的连接, 几秒钟以后就恢复了; 同时监控系统的内存使用率出现了异常的骤降; MySQL案例-mysqld got signal 11(补充) 3min之后收到了报警系统的信息, 内存使用率82%; 分析: 第一时间的判断是网络的问题造成了应用层的连接断开了, 但是这种内存使用率骤降的现象不会是网络造成的; 查看MySQL的日志, 发现MySQL实例发生了crash, 相关的报错信息如下: 点击(此处)折叠或打开 07:42:44 UTC - mysqld got signal 11 ; This could be because you hit a bug. It is also possible that this binary or one of the libraries it was linked against is corrupt, improperly built, or misconfigured. This error can also be caused by malfunctioning hardware. Attempting to collect some information that could help diagnose the problem. As this is a crash and something is definitely wrong, the information collection process might fail. key_buffer_size=8388608 read_buffer_size=16777216 max_used_connections=29 max_threads=5000 thread_count=32 connection_count=22 It is possible that mysqld could use up to key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 245834871 K bytes of memory Hope that is ok; if not, decrease some variables in the equation. Thread pointer: 0x7f607c0072c0 Attempting backtrace. You can use the following information to find out where mysqld died. If you see no messages after this, something went terribly wrong... stack_bottom = 7f6141b36e80 thread_stack 0x40000 /usr/sbin/mysqld(my_print_stacktrace+0x2c)[0xe77fec] /usr/sbin/mysqld(handle_fatal_signal+0x459)[0x7a7019] /lib/x86_64-linux-gnu/libpthread.so.0(+0xf8d0)[0x7f643257a8d0] /usr/sbin/mysqld(_ZN16Partition_helper25handle_ordered_index_scanEPh+0x5c)[0xbbabec] /usr/sbin/mysqld(_ZN7handler13ha_index_lastEPh+0x1b0)[0x7f4410] /usr/sbin/mysqld(_Z14join_read_lastP7QEP_TAB+0x65)[0xc1f605] /usr/sbin/mysqld(_Z10sub_selectP4JOINP7QEP_TABb+0x11b)[0xc25e4b] /usr/sbin/mysqld(_ZN4JOIN4execEv+0x3b8)[0xc1ea78] /usr/sbin/mysqld(_Z12handle_queryP3THDP3LEXP12Query_resultyy+0x238)[0xc8e408] /usr/sbin/mysqld[0x770ccf] /usr/sbin/mysqld(_Z21mysql_execute_commandP3THDb+0x3403)[0xc51103] /usr/sbin/mysqld(_Z11mysql_parseP3THDP12Parser_state+0x3ad)[0xc531bd] /usr/sbin/mysqld(_Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command+0x817)[0xc53a47] /usr/sbin/mysqld(_Z10do_commandP3THD+0x18f)[0xc54faf] /usr/sbin/mysqld(handle_connection+0x278)[0xd108d8] /usr/sbin/mysqld(pfs_spawn_thread+0x1b4)[0xe90784] /lib/x86_64-linux-gnu/libpthread.so.0(+0x80a4)[0x7f64325730a4] /lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7f6430e1b87d] Trying to get some variables. Some pointers may be invalid and cause the dump to abort. Query (7f607c015ad0): select * from test where time>='2016-07-29 00:00:00' and time<='2016-07-29 23:59:59' and tag in (2,3,6) order by id desc limit 2000 Connection ID (thread ID): 138760 Status: NOT_KILLED The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains information that should help you find out what is causing the crash. 2016-07-29T07:42:45.661724Z mysqld_safe Number of processes running now: 0 2016-07-29T07:42:45.664516Z mysqld_safe mysqld restarted 2016-07-29T15:42:45.991109+08:00 0 [Note] /usr/sbin/mysqld (mysqld 5.7.12-log) starting as process 8367 ... 首先是第一部分的信息: 点击(此处)折叠或打开 mysqld got signal 11 ; 通过perror命令(感谢@杨奇龙的场外援助..._(:з」∠)_...)看到ErrorCode的信息: 点击(此处)折叠或打开 Resource temporarily unavailable 代表MySQL发现某一项资源临时不可用, 应该是资源耗尽 or 申请失败等情况; 然后是第二部分信息: 点击(此处)折叠或打开 It is possible that mysqld could use up to key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 245834871 K bytes of memory 这一段计算了当前配置下, 需要的最大内存数, 大概换算了一下, 是234G; 这么高, 明显是有问题的, 联想到82%内存使用率的报警信息, 推测是内存耗尽造成的; 用max_used_connections来算一下使用的内存的话,有约1.5G; 加上BP的9.6G, 有11G了, 算上MySQL本身占用的一部分内存, 确实达到了比较高的程度; 但是看了一下kernel和message, 都没有发现系统出现OOM的日志, 应该不是系统kill的; 再看看堆栈相关的信息, 在里面记录了MySQL crash时的状态; 点击(此处)折叠或打开 stack_bottom = 7f6141b36e80 thread_stack 0x40000 /usr/sbin/mysqld(my_print_stacktrace+0x2c)[0xe77fec] /usr/sbin/mysqld(handle_fatal_signal+0x459)[0x7a7019] /lib/x86_64-linux-gnu/libpthread.so.0(+0xf8d0)[0x7f643257a8d0] /usr/sbin/mysqld(_ZN16Partition_helper25handle_ordered_index_scanEPh+0x5c)[0xbbabec] /usr/sbin/mysqld(_ZN7handler13ha_index_lastEPh+0x1b0)[0x7f4410] /usr/sbin/mysqld(_Z14join_read_lastP7QEP_TAB+0x65)[0xc1f605] /usr/sbin/mysqld(_Z10sub_selectP4JOINP7QEP_TABb+0x11b)[0xc25e4b] /usr/sbin/mysqld(_ZN4JOIN4execEv+0x3b8)[0xc1ea78] /usr/sbin/mysqld(_Z12handle_queryP3THDP3LEXP12Query_resultyy+0x238)[0xc8e408] /usr/sbin/mysqld[0x770ccf] /usr/sbin/mysqld(_Z21mysql_execute_commandP3THDb+0x3403)[0xc51103] /usr/sbin/mysqld(_Z11mysql_parseP3THDP12Parser_state+0x3ad)[0xc531bd] /usr/sbin/mysqld(_Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command+0x817)[0xc53a47] /usr/sbin/mysqld(_Z10do_commandP3THD+0x18f)[0xc54faf] /usr/sbin/mysqld(handle_connection+0x278)[0xd108d8] /usr/sbin/mysqld(pfs_spawn_thread+0x1b4)[0xe90784] /lib/x86_64-linux-gnu/libpthread.so.0(+0x80a4)[0x7f64325730a4] /lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7f6430e1b87d] 从红字等地方的信息, 可以推断出当时MySQL是正在执行查询, 这些查询中有join, 也有subquery, 且查询的表包含了分区表; 可以预料到在crash的时候, MySQL执行这些语句时肯定需要申请一部分join用的buffer, 同时子查询也会建立临时表, 都需要占用内存空间; 同时还有分区表的使用, 看了一下当时候分区表的大小: MySQL案例-mysqld got signal 11(补充)MySQL案例-mysqld got signal 11(补充) 发现当天的数据超过了BP的大小, 且用到分区表的查询走的全表扫描, 并且还有order by, 会用到sort的buffer, 且由于全表扫描的数据很多, 这个buffer有可能是需要申请满的; 综合这些信息, 基本确认是内存耗尽造成了MySQL crash; 那么根据堆栈的信息尝试还原crash时的场景: 在内存占用率很高的情况下, MySQL thread在执行较大表的查询时, 无法再申请到足够的内存(sort的buffer, join的buffer等), 因此发生了crash; 处理方式: 最终把BP从9.6G调整为9G, 并把sort, read等buffer的数值调整到了4M, 其他的buffer也调低了; PS: 算是疏忽吧, 因为说在生产环境已经用这么一套配置很久了, 没出过问题, 所以也没有仔细的排查配置文件中的设置; PSS: sort的buffer原来是多少? 32M...sort的buffer还是per thread的...失职了..._(:з」∠)_ -------------------------------------------------------------------------------------------------后续--------------------------------------------------------------------------------------------------------------- 峰回路转.....在调整了buffer的数量以后, 不可能再出现内存不够的现象了, 然后crash的现象重现了; 而且是主库和备库在非常短的时间内都发生了crash; 报错信息除了pointer不同以外, 堆栈的信息也是完全一致; 包括那个语句; 在之前出问题的时候, 记录了一条语句: 点击(此处)折叠或打开 select * from test where time>='2016-07-29 00:00:00' and time<='2016-07-29 23:59:59' and tag in (2,3,6) order by id desc limit 2000 在后来重现的时候, 两次crash的语句中, 记录的是同样的语句, (而且堆栈的输出信息也是完全一样) , 仅仅只是时间不一样: 点击(此处)折叠或打开 select * from test where time>='2016-08-09 00:00:00' and time<='2016-08-09 23:59:59' and tag in (2,3,6) order by id desc limit 2000 如果是因为内存or系统资源的不可用导致了crash的话, 不可能有这么巧合的事情, 都是这个语句; so, 在被拉起来的备库上跑了一下这个语句, 结果MySQL马上就crash了... 那么明显就是这个语句的问题了, order by desc + limit, 看上去并没什么问题, 看看explain的结果 虽然好久没做开发了, 但是filtered在100%的情况下, rows只有1还是挺奇怪的, 一整张表只有一行数据, 但是还有这种查询一整天的语句; 看看表的结构; 隐去生产库上的一部分信息, 留下关键的部分; 分区表的分区有问题.... 问过业务以后, 原来是这个功能还没做完, 所以表相关的操作并没有一直执行; 但是这个功能的页面没有屏蔽, 所以对应的那条语句是有可能被触发的; 考虑到用那条语句可以必现这个crash, 且输出的堆栈信息和之前完全一致, 所以确定是这个分区表的分区缺失的前提下, 触发那个查询语句的时导致了MySQL的Crash; 处理方式: 虽然最后还是找到了问题所在, 但是最开始的时候还是被buffer和内存使用率的现象误导了, too young...... PS:本来还是觉得分区表在5.7改进了一点以后, 应该还挺好用的.....恩, 现在持保留意见....._(:з」∠)_ PPS:应该不会再有后续了, 嗯嗯.... (编辑:ASP站长网) |
相关内容
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 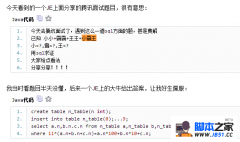 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3网友评论
推荐文章
热点阅读