MySQL innodb 全文索引使用
发布时间:2022-07-04 12:55 所属栏目:115 来源:互联网
导读:MySQL innodb 全文索引使用: 1、mysql 5.7 全文索引以下几个参数(配置文件/etc/my.cnf) #控制innodb全文检索分词的最小长度,如果设置为2那么一个汉字和一个字母将不能搜到 ngram_token_size=1 #存储在InnoDB的FULLTEXT索引中的最小词长,所说使用了ngram_t
|
MySQL innodb 全文索引使用: 1、mysql 5.7 全文索引以下几个参数(配置文件/etc/my.cnf) #控制innodb全文检索分词的最小长度,如果设置为2那么一个汉字和一个字母将不能搜到 ngram_token_size=1 #存储在InnoDB的FULLTEXT索引中的最小词长,所说使用了ngram_token_size之后就不用innodb_ft_min_token_size了,但为了保险我两个都设置了 innodb_ft_min_token_size=1 #最小分词长度,一般修改为1 ft_min_word_len = 1 2、创建表 mysql> show create table s_test; +--------+---------------------------------------------------------+ | Table | Create Table | +--------+---------------------------------------------------------+ | s_test | CREATE TABLE `s_test` ( `id` int(11) NOT NULL DEFAULT '0' COMMENT 'primary key', `uname` varchar(50) DEFAULT NULL COMMENT '用户名', `dept` int(11) DEFAULT NULL COMMENT '部门组ID', `info` varchar(200) DEFAULT NULL COMMENT '其他信息' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +--------+--------------------------------------------------------+ 1 row in set (0.00 sec) 3、创建索引 mysql> create fulltext index ix_ft_s_test_uname_info on s_test(uname,info) WITH PARSER ngram; Query OK, 0 rows affected, 1 warning (2.68 sec) Records: 0 Duplicates: 0 Warnings: 1 4、查询这张表的所有索引 mysql> show index from s_test; +--------+------------+-------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +--------+------------+-------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | s_test | 1 | ix_ft_s_test_uname_info | 1 | uname | NULL | 99750 | NULL | NULL | YES | FULLTEXT | | | | s_test | 1 | ix_ft_s_test_uname_info | 2 | info | NULL | 99750 | NULL | NULL | YES | FULLTEXT | | | +--------+------------+-------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 2 rows in set (0.00 sec) 5、查询索引详细情况 mysql> select * from mysql.innodb_index_stats where database_name='mydb' and table_name='s_test' ; +---------------+------------+------------------+---------------------+--------------+------------+-------------+-----------------------------------+ | database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description | +---------------+------------+------------------+---------------------+--------------+------------+-------------+-----------------------------------+ | mydb | s_test | FTS_DOC_ID_INDEX | 2015-10-03 14:07:18 | n_diff_pfx01 | 100672 | 20 | FTS_DOC_ID | | mydb | s_test | FTS_DOC_ID_INDEX | 2015-10-03 14:07:18 | n_leaf_pages | 121 | NULL | Number of leaf pages in the index | | mydb | s_test | FTS_DOC_ID_INDEX | 2015-10-03 14:07:18 | size | 161 | NULL | Number of pages in the index | | mydb | s_test | GEN_CLUST_INDEX | 2015-10-03 14:07:18 | n_diff_pfx01 | 99750 | 20 | DB_ROW_ID | | mydb | s_test | GEN_CLUST_INDEX | 2015-10-03 14:07:18 | n_leaf_pages | 525 | NULL | Number of leaf pages in the index | | mydb | s_test | GEN_CLUST_INDEX | 2015-10-03 14:07:18 | size | 545 | NULL | Number of pages in the index | +---------------+------------+------------------+---------------------+--------------+------------+-------------+-----------------------------------+ 6 rows in set (0.00 sec) 6、全索引查询 通过在AGAINST()函数中指定 1、IN NATURAL LANGUAGE MODE expr就是要搜寻的字符串。 2、IN NATURAL MODE WITH QUERY EXPANSION 第一次用给定的短语搜索,第二次使用给定的短语结合第一次搜索返回结果中相关性非常高的一些行进行搜索。 3、IN BOOLEAN MODE expr里有特殊字符辅助特殊的搜寻语法 查询只能按短语,不能使用中间字符 mysql> select count(*) from s_test where MATCH(uname,info) AGAINST ('a*' IN BOOLEAN MODE); +----------+ | count(*) | +----------+ | 6238 | +----------+ 1 row in set (0.02 sec) (编辑:ASP站长网) |
相关内容
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 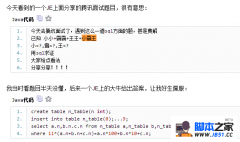 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3网友评论
推荐文章
热点阅读