数据驱动算法在机器学习中的应用
|
机器学习的概念分析 机器学习作为一个概念,与提高计算机使用算法和神经网络模型学习的能力有关,并能更快更有效地执行各种任务。机器学习或ML通过使用数据或数据集来帮助建立模型来做出决策。它可用于精简组织的决策和执行绩效。这个词是1959年由美国人阿瑟・塞缪尔(ArthurSamuel)首创的,他精通人工智能和电脑游戏。 从概念上讲,机器学习模拟了人类的脑细胞交互模式。在大脑活动中,当神经元相互交流时,这些神经元反过来使人类能够轻松地执行各种功能和任务,而不需要任何其他外部形式的支持。就像人类大脑中的神经元根据情况来解剖每个任务一样,在ML中,数据按照各种算法来预测、分类和表示,解决一个复杂问题并提出解决方案。 机器学习中的神经网络模型也是基于DonaldHebb博士在TheOrganizationofBehavior中的理论。在制定机器学习概念方面的一些显着贡献是基于1950年代IBM的ArthurSamuel的进化工作的逐步实施,他开发了一个计算机程序。该计算机程序涉及alpha-beta剪枝,用于测量跳棋游戏中每一方获胜的机会。紧随其后的是由FrankRosenblatt于1957年开发的定制机器感知器,专为图像识别而构建,导致了MercelloPelillo于1967年开发的用于基本模式识别的最近邻算法。
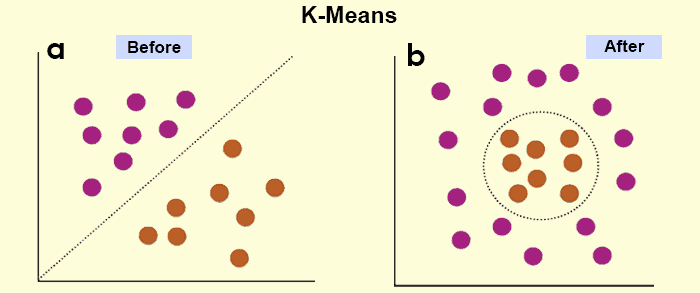
机器学习算法和模型 机器学习是基于算法和模型的校准功能。简单地说,算法可以称为利用结构化或非结构化数据产生输出的简单过程。同时,机器学习模型表示程序和程序(算法)的结合,即使用程序来达到预期的结果,完成预期的任务。 算法是一个公式,通过它可以做出预测;机器学习模型是实现算法后产生的输出的更广泛的方面。因此,在技术层面上,可以引用机器学习算法导致ML模型,而不是反之。为了理解ML算法的功能,让我们先看看机器学习中的模型。 机器学习模型分为三大类: 监督学习:在监督学习中,在不确定的情况下,通过计算证据,从已知的数据集(输入)和已知的数据响应(输出)做出预测,以开发新的数据或数据集作为响应。监督学习进一步使用分类和回归等技术来提出其他机器学习模型。无监督学习:无监督学习包括从输入数据中得出推论,而不从具有内在数据集或结构的隐藏模式中标记出响应。强化学习:在机器学习的强化学习模型中,基于试错法,在复杂环境下做出一系列决策。根据所做决定的结果,奖励和惩罚有助于最终引出回应。 现在为了详细说明机器算法做了什么,让我们以一个基于聚类的机器学习算法K-means为例。考虑了几个聚类,以k为变量。识别每个簇的中心或质心,并在其基础上定义一个数据点。在几次迭代中,数据点和集群被重新识别,一旦定义了所有中心,数据点将与每个集群对齐,并与集群中心相接近。该算法在训练数据上表现出色,有助于分类各种人工智能程序的音频检测和图像分割等复杂任务。
使机器学习成为一个进步的领域,根据业务需求探索和发展的另一个方面是它对数据处理的需求。各种形式的训练数据是机器学习的基础。从检测用于安全目的的对象到预测业务趋势,高效和高性能的算法本质上是以数据为中心的;数据集越精确,算法产生的输出就越准确。 机器学习中数据驱动的算法 在物理世界中,人类互动的大部分方面都是基于与各种无形数据的动态关系,人类的大脑每天都会执行许多简单的数据驱动计算。类似地,计算是基于机器学习中的数据或标记训练数据,这有助于基于人工智能(AI)的程序工作来增加价值。与编写程序代码自动化处理过程或对大量数据进行深入调查相比,算法的使用要可靠得多,速度也快得多。 机器学习算法是一种数学方法,在提供的数据的帮助下产生一组结果。因此,在机器学习的过程中,数据的重要性是至关重要的。由ML驱动的人工智能程序的效率取决于输入算法代码的训练数据的质量。不准确的数据集也会降低性能。 对于一个ML算法产生高价值的输出,可用性的高质量的训练数据集是必须的。训练数据集是根据人工智能应用程序的目标开发的注释或说明数据。
主要是两种类型的数据推动了机器学习算法的工作。 1.手工数据标签 2.自动数据标签 3.人工智能辅助的数据标注 在自动、手动和人工辅助数据标注方面有一些关键的区别。在手动数据标签,人群强制标签的原始数据按照共享的指导方针或技术定义附加标签。而在自动数据标注中,训练数据由程序标注,并在加载执行前检查其准确性。而且,人工智能辅助的数据标记需要自动程序和人工努力来产生高质量的训练数据。 基于数据的算法在现实世界中的应用 算法和技术适用于各行业和经济部门。在数字技术和数据驱动的生态系统时代,复杂的需求面临着高效数据创建和开发的挑战,在智慧城市、网络安全、智能医疗、社交媒体和商业等领域,ML也在不断实现数据结构化和可用数据处理,以更好地做出决策。提高绩效,增强业务可持续性。 在卫生部门,人工智能程序正在执行由高度可用的训练数据驱动的任务。这些数据使诸如二十亿等健康应用程序通过检测对象、动作、属性、视听输入、语音输入、神经网络、语音输出、身体控制等来帮助客户跟踪他们的健康训练计划的进度。,正在帮助支持AI的应用程序解码复杂的任务,例如: 了解现场理解口语理解对象和动作通过聊天机器人生成口语控制助理的身体理解人类的姿势将视觉概念与文字等联系起来行为 在金融等领域,机器学习算法正在帮助企业发现未来的投资机会;同时,对于政府部门,ML算法通过简单地处理来自多个来源的复杂数据,帮助处理欺诈、身份盗窃和提高公共工程的效率。此外,随着数据量越来越大,机器学习(ML)正通过使用复杂的数据集来增加价值,帮助垂直企业应对未来的诸多挑战。 尾注 理想情况下,机器学习被用于处理涉及大量数据的复杂计算任务,而没有静态公式来得出结果。多年来,随着机器学习领域的不断研究和发展,医疗、能源生产、汽车、航空航天、制造业和金融等商业部门都从机器学习模式中获益。机器学习模型和算法正在帮助解决特定行业的问题,并通过对象检测、信用评分、交易预测、DNA测序和预测性维护提供未来的全行业解决方案。 (编辑:ASP站长网) |


 不只自动驾驶,激光雷
不只自动驾驶,激光雷 移动机器人领域再迎大
移动机器人领域再迎大 探索智能家居中的物联
探索智能家居中的物联 RFID新应用:识别被盗
RFID新应用:识别被盗 摘下长江零跑标识!零
摘下长江零跑标识!零